利用AI模型来预测病毒或谣言的传播走向,已经不再是什么新鲜事物。
要知道,现实情况往往比训练AI的数据集复杂N倍,而研究人员打造的模型,往往只是研究传播对象的前几个步骤,然后将这个速率引入复杂的数学模型之中,来预测传播的广度和速度。
但如果病原体发生变异,或新闻内容被修改,传播速度和方式也将发生变化,这时候,原本的AI模型还能成功应对呢?
这也使我们不得不思考更进一步的问题——将AI看成防范病毒/谣言的利器,但技术本身也必须在复杂环境中持续迭代。
七十二变:比疾病更难预测的“病毒”
疾病变异,可以通过基因比对来追根溯源。那么信息变异呢?
在以T为单位的网络世界,内容信息往往会以闪电般的速度在社交媒体上传播。在这次疫情中大家可能也发现了,谣言往往轻易获得“万转”,而辟谣信息的转发却十分可怜。
这也说明了一个传播学的难题,一条信息是否会传播,取决于原始信息是如何被篡改的。
有些错误是故意的,也就是“造谣”。但有的改变则是出于增加电话、加入交互等成分而自然发展出来的。
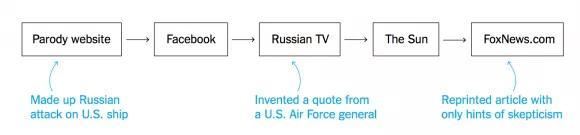
比如一则关于2014年俄罗斯战斗机与美国驱逐舰在黑海对峙的旧闻,经过一些八卦网站(Parody website)的篡改,变成了:俄罗斯空军配备一种神秘电磁武器,瞬间弄瘫了整艘美国军舰。
此消息经过社交媒体发酵,最后甚至登上了主流媒体福克斯新闻网站的头条。
那么,一条看似枯燥的信息是否能演变成病毒式传播的博文,能够预测出来吗?
此时,原本用于预测流行病趋势的传染病动力学,就开始与信息传播联系到了一起。
早在上个世纪,科学家们就开始基于传染病动力学模型,研究复杂网络下信息的传播模型了。
经典的谣言传播模型理论研究源于20世纪 60年代 。
1965年,研究者Dalay和Kendall提出了谣言传播的数学模型,后来人们命名该模型为DK模型。它把人群按照谣言传播效果,分成谣言易染类人群、谣言感染类人群及谣言移出类人群,认为其中两类会以随机过程来相互转换。
到了1973年,麦基和汤普森两人对当时主流的谣言传播模型DK模型进行了改进,引入了免疫人群。
2001年,Zanetee则将复杂网络引入到谣言传播模型中,建立了具有网络拓扑结构特征的传播模型。2004年,莫瑞奥等人在小世界网络和无标度网络中研究了谣言传播动力学。
但是,这些模型均未将信息老化理论考虑进去。
到了2011年,中国研究者则将以往机制引入谣言传播类型,认为人们关注谣言的热度会随着时间的推移而下降,尤其是在纷繁复杂的网络世界中,人们的吸引力也容易被其他事物所转移。无知者转化为谣言传播者或真相传播者的概率会下降,并将其慢慢遗忘。

诚然,数学模型严密的逻辑性和抽象性,为舆论管理带来了一定的预测可能性。
但其中有两个问题却始终存在:
一是时间滞后。谣言传播与传染病传播在机理上有很多的相似性,就像病毒存在潜伏期一样,网络谣言从被更改、发布、发酵、传播、消失等一系列过程,个体的时间滞后程度都不一样。有的可能当下非常关心,有的则沉迷学业一个月后才赶来吃瓜……种种不确定性,也给预测网络信息传播带来了一定的难度。
其次,则是变异突发。正如同我们很难追溯病毒是如何在扩散过程中逐渐变异的,对谣言的改造和增删,都有可能改变其传播路径与效果。比如新冠期间,从宠物可能感染新型肺炎,到养宠可以预防,再到有宠物被检测出阳性……反转一波接一波,有的则是披着辟谣皮的新谣言,这些都会让对信息的预测出现误差。
如果不考虑随着时间的推移可能发生的变化,那么在预测生病人数或接触到一条信息的人数时,肯定会出错。
不断趋近真相:让AI模仿现实
怎么办呢?答案是只有让模型与现实之间的差异尽可能地小,从而提高预测的准确率。
前不久《美国国家科学院院刊》(PNAS)上发表的一项新研究,来自卡内基梅隆大学(Carnegie Mellon University)的研究人员就将信息变异这一关键变量引入到了数学模型之中。

他们在现实世界的网络中对数千种计算机模拟的流行病进行了数千次模拟测试,比如一个是美国某高中学生、教师和工作人员之间的联系网络Twitter,另一个是法国里昂一家医院的工作人员和病人之间的联系网络。
借助实时数据跟踪病原体的进化或信息,“证明了我们的模型在现实世界的网络上有效,更精确。”该研究的第一作者Rashad Eletreby表示。
而实现这一点的意义,让人类对病毒/谣言的传播预测距离现实又近了一步。
有了AI模型,世界还会失序吗?
如果病毒/信息的传播可以被精准预测,是不是不会再上演那些无奈的故事?
比如2003 的SARS疫情,学者们就建立了大量的动力学模型研究其传播规律和趋势,以及各种隔离预防措施的强度对控制流行的影响,来为决策部门提供参考。
还有网络上广泛传播的“双黄连可预防新冠病毒”、“食用大蒜可以杀灭新冠病毒”等伪科学谣言,如果能及时地预测变化趋势,介入并引导,民众盲目哄抢、囤积事件是不是就不会发生?
显然,就目前的研究成果来看,想要以100%的准确率,预测病毒或假新闻传播,AI模型还不是那味灵丹妙药。

首先,病毒/信息的大范围流通一定会出现歧变,而目前的相关研究和数值都比较匮乏,这也决定了即使训练出了相关模型,也很难快速为重大公共卫生事件起到有效的作用。
另外,不同事件周期中人群对信息(谣言)的易感度是不同的,除了个体性差异之外,对组织的信任与认同、信息公开的精准性等,都会直接影响传播结果。
比如在环境危险性较高的时候,如果人们得到的信息又比较模糊,那么谣言就很容易被相信和传播。在地震、海啸等灾难性实践中,就屡屡出现哄抢等行为。
所以说,不同群体在不同情境下的心理状态,会直接影响到预测模型的准确率。
当然,上述不确定性也为我们寻求AI之外的解药提供了线索。
除了依靠机器来完成预测,在引发负面传播之前就实现合理控制,从源头建立整个社会的“谣言免疫力”,恐怕才是更重要的。

目前看来,有三个关键因素是值得注意的:
1.精确有效的信息释放。
在出现传染病/谣言传播等情况时,每个人都会主动去寻求与自身休戚相关的信息,以便更精确的感知环境来做出决策。
2004年,两位学者就通过分析280条网络谣言,发现很大比例的谣言主体都是在寻求事实中希望进一步解决问题的。
一旦某些重要信息反而模糊性较强的时候,就很容易引发焦虑,从而导致一些消极、非官方的渠道来探寻事实。所以,提供精确有效的信息,能够极大地缓解个体的焦虑情绪,从而降低信息传播的负面影响。
2.重视社群节点的管理。
所有社交网络都是借助一个个关键“节点”来实现连接的,谣言亦如是。
而在比较亲密的社交关系中,消极谣言更容易被用来增加彼此的联系,因为可以通过分享来共同寻找解决办法。所以不要再抱怨你的老母亲老父亲总在家庭群里传播谣言帖了,在控制网络谣言传播上,让亲密社交中的关键人分享有价值的信息,能够有效狙击消极信息。这也为疫情防控中的舆论管理指出了更为清晰的路径。
3.提高个人的抗谣能力。
当大环境与小氛围都能够得到有效控制,那么个人在信息传播过程中成为谣言感染者的可能就会直接降低。一些耸人听闻的谣言,只要仔细推敲,就会不攻自破,抢购“双黄莲蓉月饼”的闹剧可能也就不会发生了。
在《大流感:最致命瘟疫的史诗》的结尾,约翰巴里写道——恐惧源于蒙昧,一旦怪兽露出原型,恐惧就凝缩成具体形象,不复存在了。
这也是AI持续进化的意义所在,只要人类能够看清病毒/谣言的每一次畸变,自然也就打破了恐惧。