看一眼菜品图就知道怎么做、能给植物看病、能把手写英文准确翻译成中文、还能精准分析财报数据……多模态能力再次升级!今天,阿里国际AI团队发布了一款多模态大模型Ovis,在图像理解任务上不断突破极限,多种具体的子类任务中均达到了SOTA(最新技术)水平。
多模态大模型能够处理和理解多种不同类型的数据输入,例如文本、图像。与大型语言模型(LLMs)相比,大语言模型在处理和生成文本数据方面有专长,而多模态大模型能够处理非文本数据,如图像等等。
根据多模态权威综合评测平台OpenCompass的数据,Ovis1.6-Gemma2-9B在30B参数以下的模型中取得了综合排名第一,赶超MiniCPM-V-2.6等行业优秀大模型。
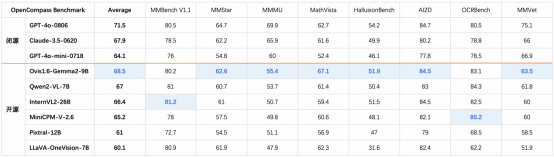
图:Ovis在OpenCompass上的测评数据情况
据介绍,Ovis能够在数学推理问答、物体识别、文本提取和复杂任务决策等方面展现出色表现。例如,Ovis可以准确回答数学问题,识别花的品种,支持多种语言的文本提取,甚至可以识别手写字体和复杂的数学公式。
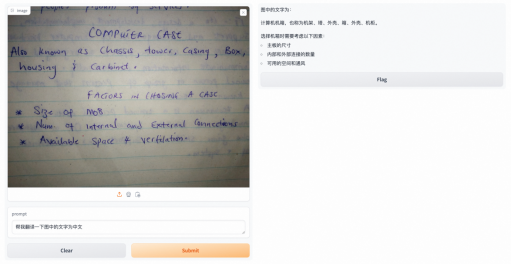
案例1:Ovis对手写文案的识别及翻译能力
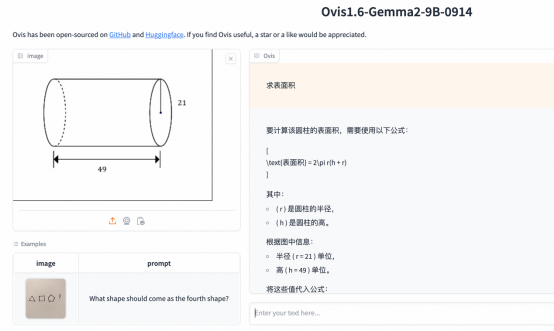
案例2:Ovis对复杂数学公式的处理能力
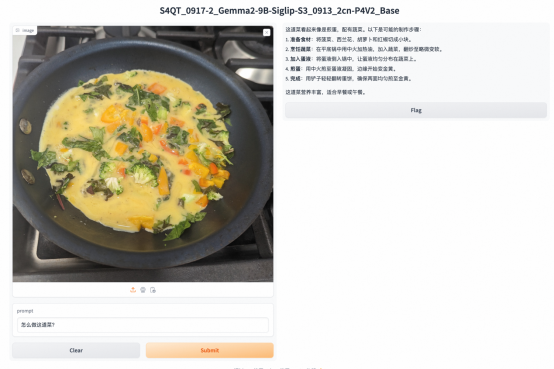
案例3:Ovis通过对图片的识别处理能够给出菜谱
具体来说,Ovis模型有五大优点:
1、创新架构设计:可学习的视觉嵌入词表:首次引入,将连续的视觉特征转换为概率化的视觉token,再经由视觉嵌入词表加权生成结构化的视觉嵌入,克服了大部分MLLM中MLP连接器架构的局限性,大幅提升多模态任务表现。
2、高分图像处理:动态子图方案:支持处理极端长宽比的图像,兼容高分辨率图像,展现出色的图像理解能力。
3、全面数据优化:多方向数据集覆盖:全面覆盖Caption、VQA、OCR、Table、Chart等各个多模态数据方向,显著提升多模态问答、指令跟随等任务表现。
4、卓越模型性能:Ovis展现出了优异的榜单表现。在多模态权威综合评测Opencompass上,Ovis1.6-Gemma2-9B在30B参数以下的模型中取得了综合排名第一,超过了Qwen2-VL-7B、MiniCPM-V-2.6等模型。尤其在数学问答等方向表现媲美70B参数模型;在幻觉等任务中,Ovis-1.6的幻觉现象和错误率显著低于同级别的模型,展现了更高的生成文本质量和准确性。
5、全部开源可商用:Ovis系列模型License采用 Apache 2.0。Ovis 1.0、1.5的数据、模型、训练和推理代码都已全部开源,可复现。Ovis1.6系列中的Ovis1.6-Gemma2-9B也已开源权重。
在AI领域,多模态大模型的应用场景非常广泛,包括但不限于自动驾驶、医疗诊断、视频内容理解、图像描述生成、视觉问答等。例如,在自动驾驶领域,多模态大模型可以整合来自摄像头、雷达和激光雷达的数据,以实现更精准的环境感知和决策。由于多模态大模型能够学习如何联合理解和生成跨多种模式的信息,也被视为朝向通用人工智能的下一个步骤。
根据此前媒体报道,阿里国际在去年成立了一支AI团队,目前已经在40多个电商场景里测试了AI能力,覆盖跨境电商全链路,包括商品图文、营销、搜索、广告投放、SEO、客服、退款、店铺装修等,其中多个应用场景均基于Ovis模型进行开发,已帮助50万中小商家、对1亿款商品进行了信息优化。据介绍,商家的AI需求不断增长,近半年的数据显示,平均每两个月,商家对于AI的调用量就翻1倍。
附相关链接:
论文arXiv: https://arxiv.org/abs/2405.20797
Github: https://github.com/AIDC-AI/Ovis
Huggingface: https://huggingface.co/AIDC-AI/Ovis1.6-Gemma2-9B
Demo: https://huggingface.co/spaces/AIDC-AI/Ovis1.6-Gemma2-9B
雷峰网(公众号:雷峰网)
雷峰网版权文章,未经授权禁止转载。